ACL 2026
Agentic Very Long Video Understanding
Presents an agentic framework for very long video understanding that combines visual search, transcript search, and entity-graph reasoning.
Accepted to ACL 2026.
My research broadly lies at the intersection of vision and language. Specifically, I am interested in grounding language in images and videos which entails associating language phrases to visual concepts. Such visual-linguistic associations encompass objects, actions, their relations and are crucial to rich image and video understanding.
Presents an agentic framework for very long video understanding that combines visual search, transcript search, and entity-graph reasoning.
Accepted to ACL 2026.

Introduces a differential visual reasoning framework that uses preference-driven rollouts to improve fine-grained image recognition.
Published as a conference paper at ICLR 2026.
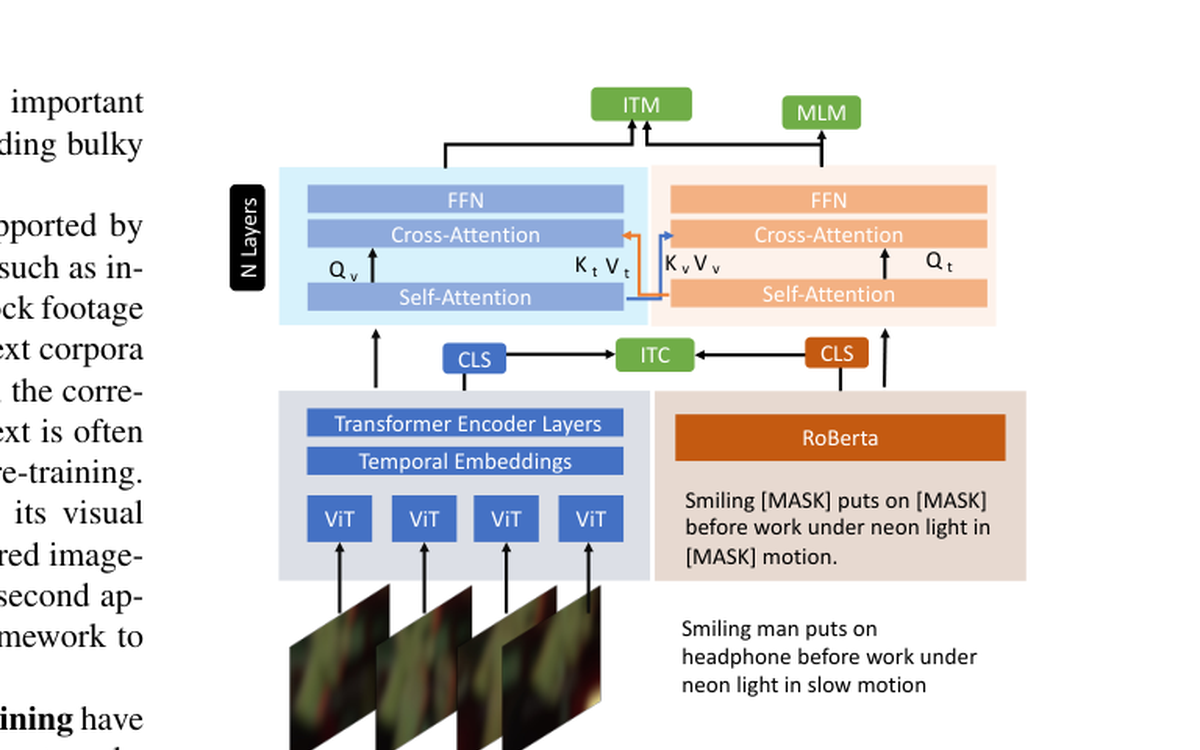
Studies how task-specific vision-language pre-training can transfer from image-text supervision into broader image and video reasoning tasks.
Presented at WACV 2024.
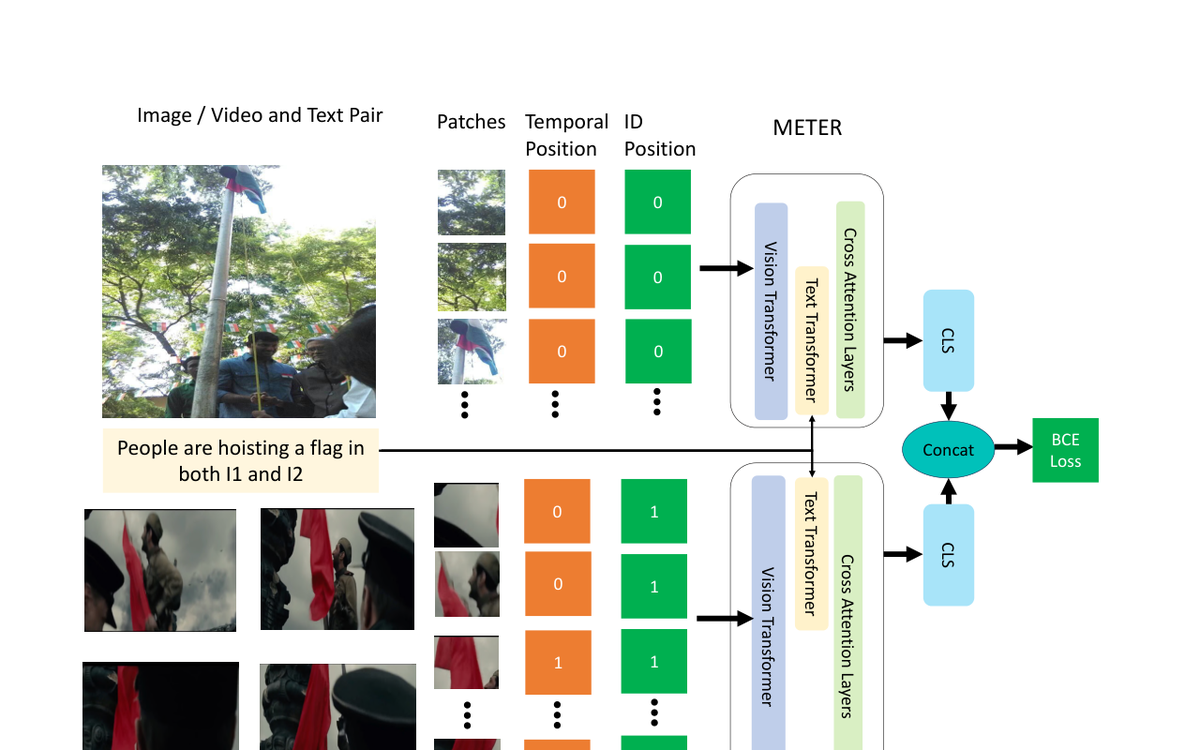
Explores iterative alignment strategies for learning from video and text pairs that are only weakly or noisily aligned.
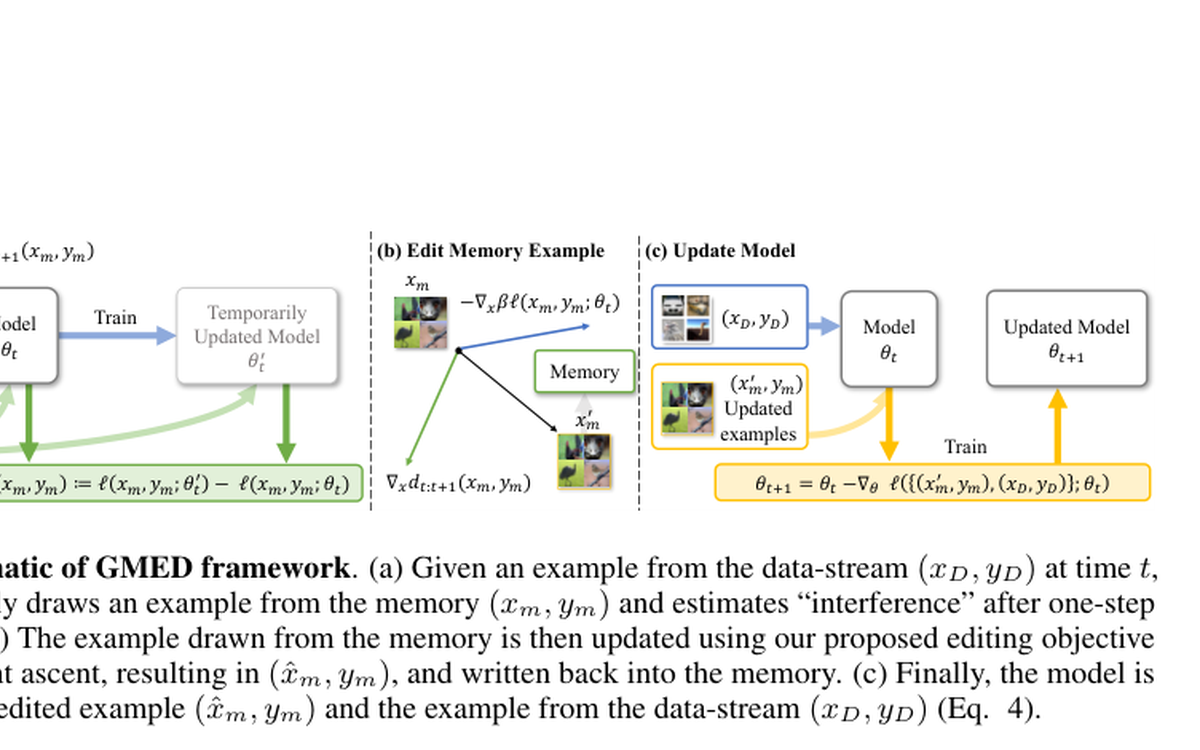
Introduces memory editing mechanisms for task-free continual learning to better control forgetting without relying on explicit task boundaries.
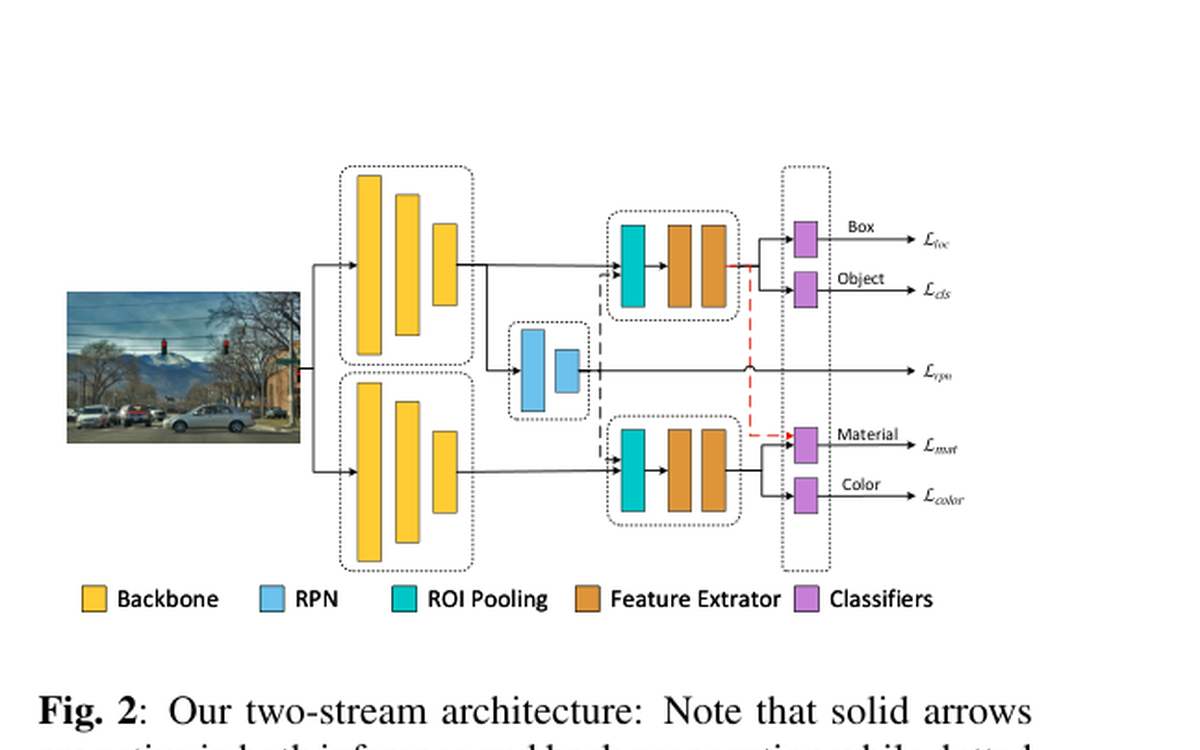
Investigates how disentangling feature representations can jointly improve object detection and attribute recognition.
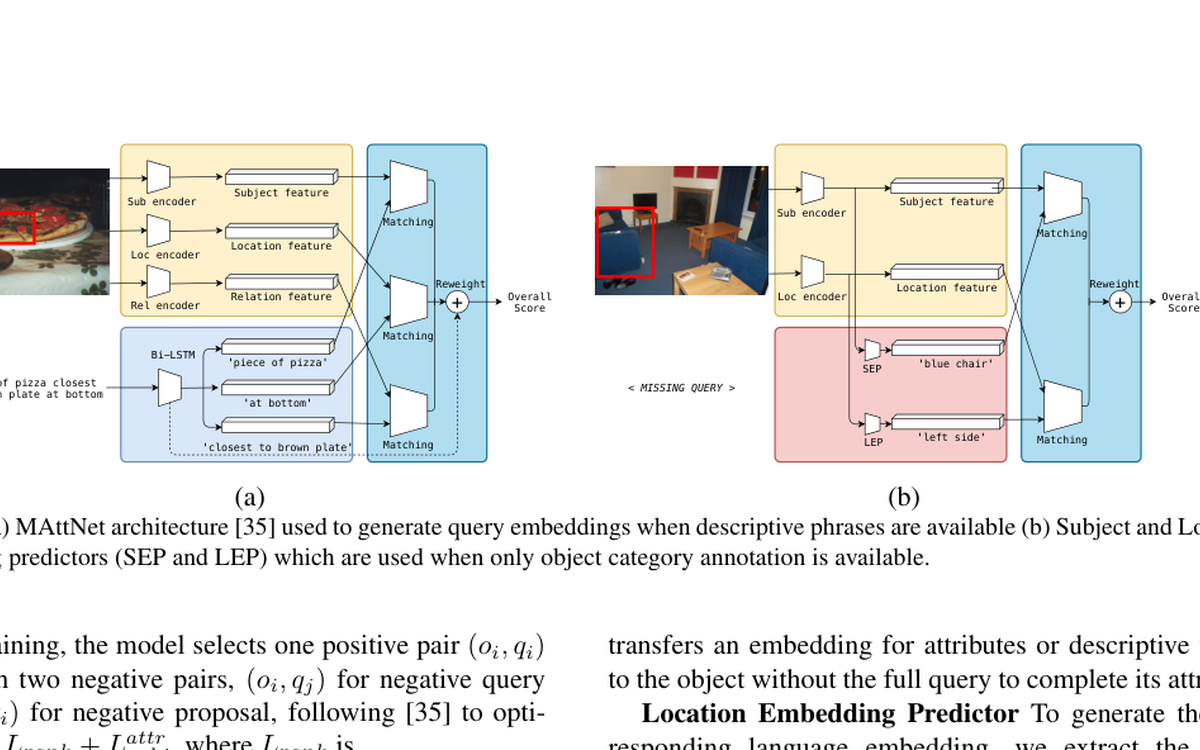
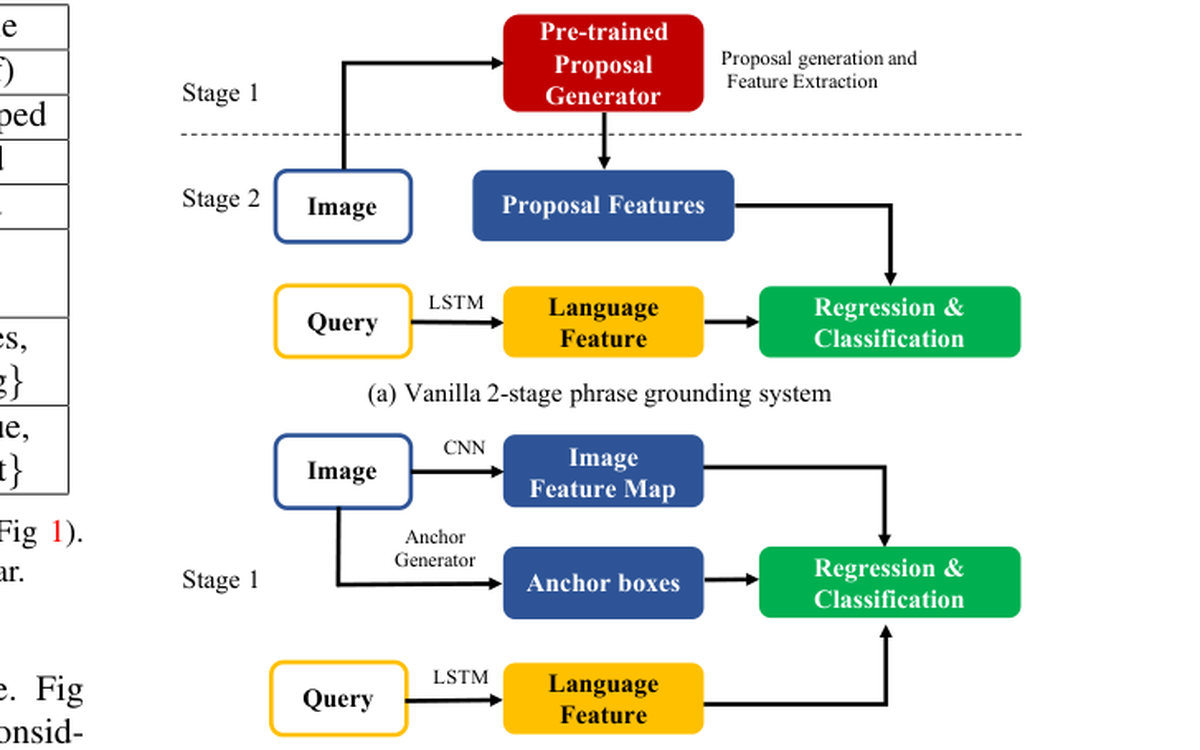
Shows how object-level structure can improve semi-supervised phrase grounding by making fuller use of image content.
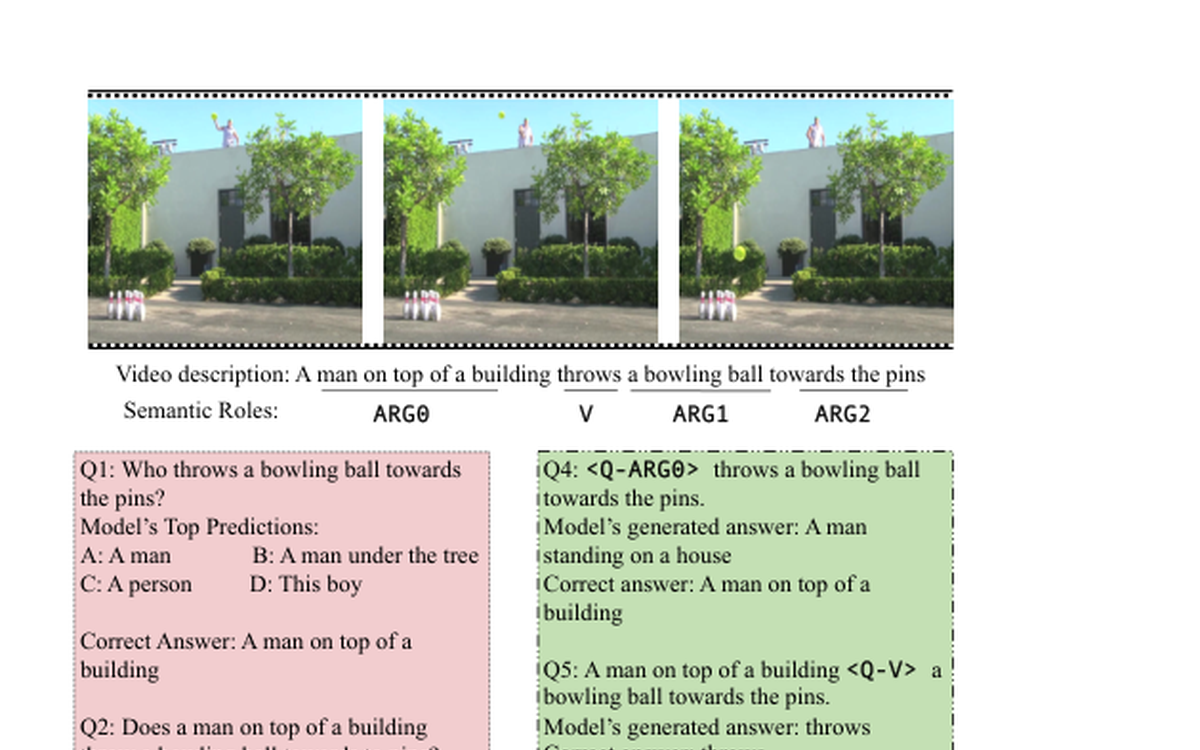
Connects phrase-level supervision and semantic-role structure to improve video question answering beyond surface text matching.

Presents a semantic-role-centered formulation for video understanding, pairing structured roles with action-centric video reasoning.
Built into the VidSitu benchmark and project site.
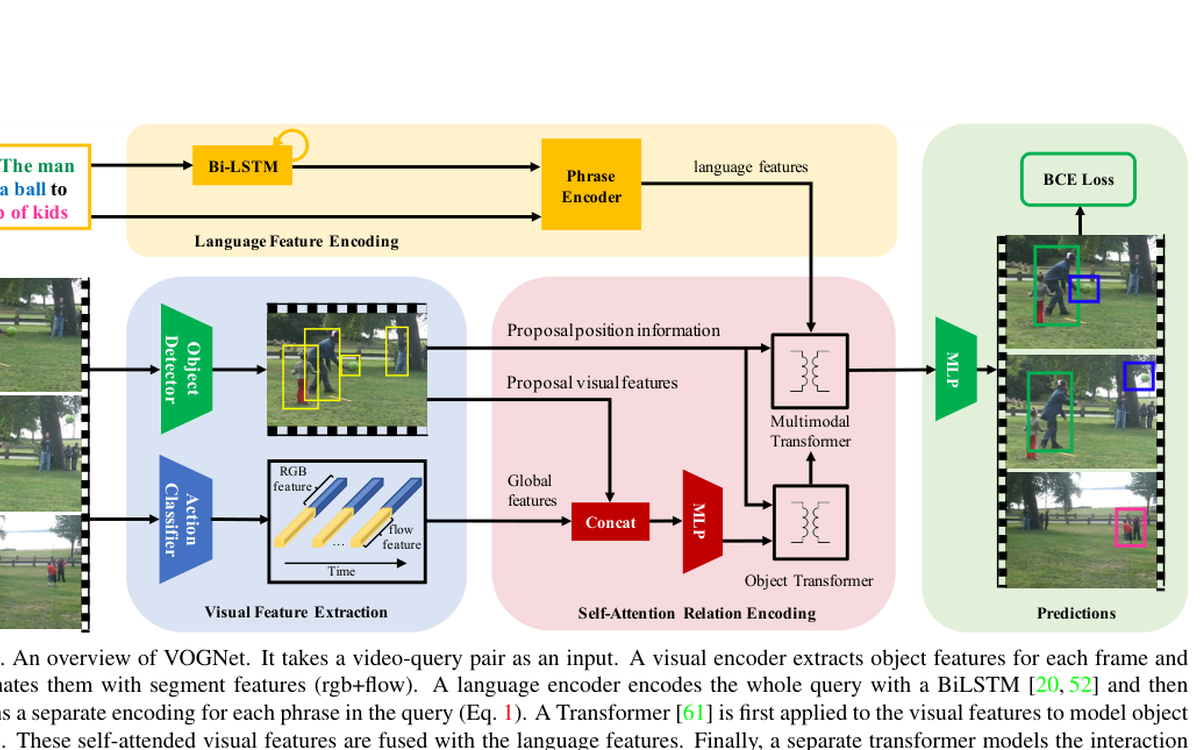
Grounds video objects through the semantic structure of language, tying textual roles to video evidence over time.

Combines visually grounded language learning with continual learning, focusing on compositional phrase understanding over time.