
ACL 2026
Agentic Very Long Video Understanding
Presents an agentic framework for very long video understanding that combines visual search, transcript search, and entity-graph reasoning.
Accepted to ACL 2026.
About me
I am a Senior Research Scientist at Meta Reality Labs. I completed my PhD at the University of Southern California (USC), Los Angeles, where I was advised by Prof. Ram Nevatia. My work centers on grounding language in visual data, especially images and videos, and on building models that connect objects, actions, and their relations for richer multimodal understanding.
My current research sits at the intersection of vision and language, with an emphasis on grounded video understanding, multimodal reasoning, and research systems that connect language to objects, actions, and their relations.
Before USC, I completed my BTech in Electrical Engineering at the Indian Institute of Technology Bombay in 2018, where I worked with Prof. Subhasis Chaudhuri on graph CNNs for disease detection from ECG signals.
Across academia and industry, I have also worked with Meta AI, PRIOR@AI2, Wadhwani AI, USC, and Aalto University.

News And Updates
July 2025
Senior Research Scientist at Meta Reality Labs, continuing work with the Surreal team.
June 2025
Attended CVPR 2025 and participated at the Meta booth.
June 2024
Joined Meta in the Surreal Team.
May 2024
Attended the hooding ceremony and officially submitted the thesis.
April 2024
Defended the thesis.
Jan 2024
Presented "Leveraging Task-Specific Pre-Training To Reason Across Images and Videos" at WACV 2024.
2023
Served as a reviewer for ICML, ACL, ICCV, EMNLP, NeurIPS, BMVC, WACV, CVPR, AURO, and TPAMI.
Jun 2021
Presented "Visual Semantic Role Labeling for Video Understanding" at CVPR 2021.
Jun 2021
Presented "Video Question Answering with Phrases via Semantic Roles" at NAACL 2021.
May 2021
Recognized as an Outstanding Reviewer at CVPR 2021.
April 2021
Released Video-QAP and VidSitu materials publicly.
June 2020
Presented "Video Object Grounding using Semantic Roles in Language Description" at CVPR 2020.
Oct 2019
Presented "Zero-Shot Grounding of Objects from Natural Language Queries" at ICCV 2019.
Recent and Selected Publications
Presents an agentic framework for very long video understanding that combines visual search, transcript search, and entity-graph reasoning.
Accepted to ACL 2026.

Introduces a differential visual reasoning framework that uses preference-driven rollouts to improve fine-grained image recognition.
Published as a conference paper at ICLR 2026.

Presents a semantic-role-centered formulation for video understanding, pairing structured roles with action-centric video reasoning.
Built into the VidSitu benchmark and project site.
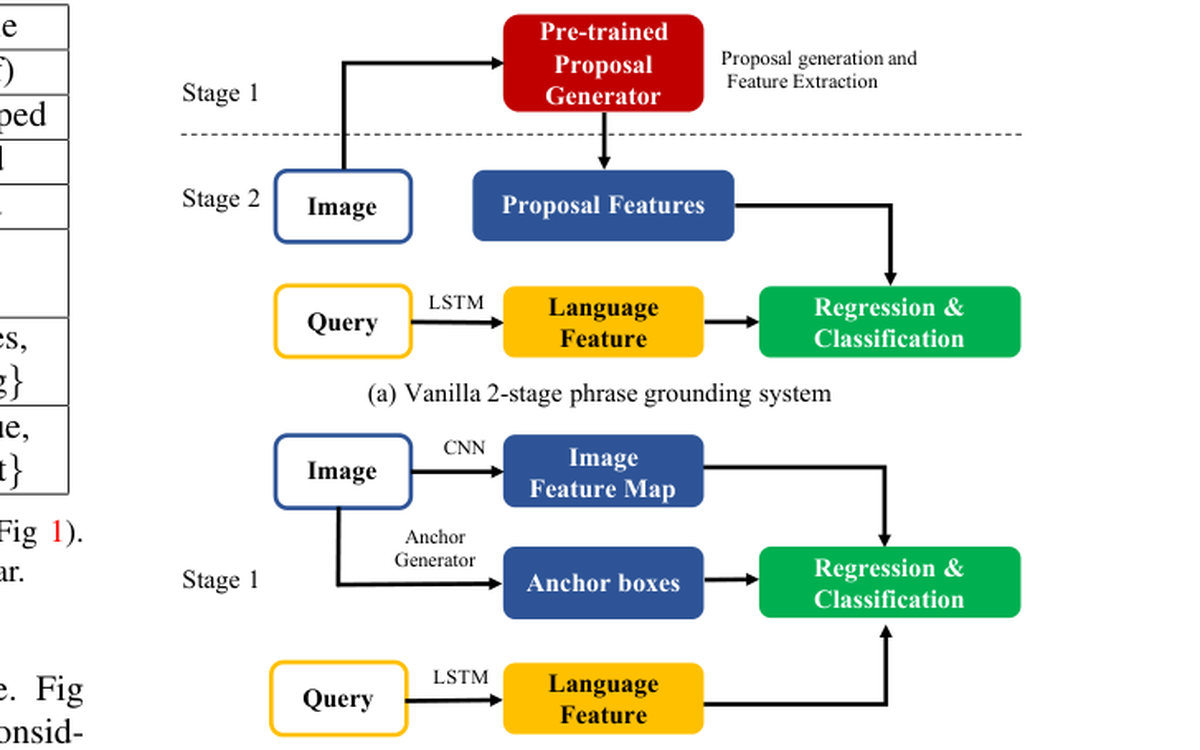
Addresses phrase grounding in the zero-shot setting, focusing on transferring to unseen queries and concepts.
Accepted as an oral presentation at ICCV 2019.